Structuring our Python code#
So we’ve started building some python code on GitHub to help answer some of your research questions. Perhaps we’ve made a few subdirectories to separate notebooks from scripts, with another directory for qsub jobs etc.
Now, what if we want to share this code with someone else? Or if we want look at a colleague’s code and import it as modules within our own code?
Give the interconnectivity of the python universe, which encompasses innumerable disciplines and applications (from climate science, machine learning, web development, all the way to embedded logic controllers at the CERN particle accelerators), has the python community arrived at common ways to structure python code packages?
The answer, of course, is yes.
Portability#
A key concept of code development is ‘portability’. Portability allows us to
Run our code on different computing platforms (e.g.
gadi, your laptop)Run our code on different environments
Share our code with other users who can then run it
When we first build our code, we will often ‘hard code’ segments of code related to directory paths, user directories etc. If we share this code with someone else, they will to scan through every line of code with an explicit path to a directory of file, that is unique to a filesystem on a given platform.
A better way to manage input and output data flows is by using environment and configuration files.
Environment and configuration files#
Let’s return to the solar code we discussed in the parallel python examples. The code to to analysis the solar irradiance data is located at
21centuryweather/software_engineering_demos
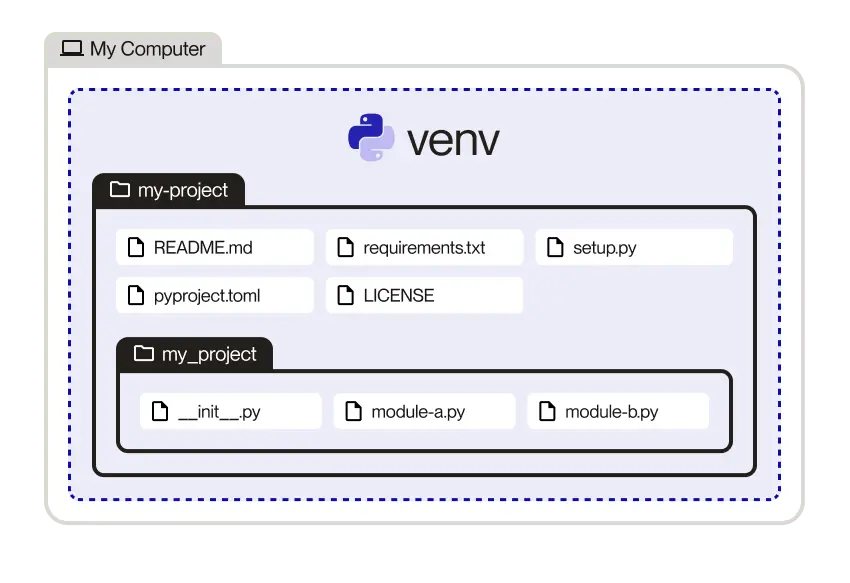
There are three files sitting in the main project directory solar_example:
The README.md is a markdown file which is self-explanatory. Anyone who is given your code should be able to view the README.md file and understand what your code does. The length and complexity of the README.md should be appropriate for the complexity of the associated python project. Given that our solar_example code is very simple, our README.md is very succinct.
The env.sh file is a bash script designed to help with ‘portability’. This file loads the python environment analysis3 and then exports the definition of the project ROOT directory, i.e. the location where a user has cloned this repository. When a user clones this code, all they have to do is change the definition of ROOT and the all other filepaths used by the python modules inside the project will be defined,
We define the MODULES environment (where we store most of our python code) and then add this to the python PATH environment, which is a universal environment variable used by all python interpreters on Linux/Unix-based machines to search for python code.
Note
Inside a python interactive session or notebook, the sys.path variable defines the directories where the python interpreter searches for modules. All python interpreters automatically add the directories defined in PYTHONPATH to sys.path.
We then export these variables so they are valid across all programs running in this current environment (whether it’s an interactive login session or inside the PBS job queue.)
Note
A python ‘module’ refers to a script (usually containing one or two functions) that can be imported by other sections of python code using the import statement.
This env.sh file helps any user on gadi deploy this package. However, the file itself assumes it will only be run on gadi, and all users will have hh5 project membership. If you wanted to run this project on other platform (e.g. your laptop) you would need to write separate environment file for that system. You might need to build a new directory (e.g. envs) to store several environment files, one for each computing platform.
The config.py file is some python code that reads in the environment variables declared earlier in env.sh and also defines the location of the input and output data on gadi.
This is designed so that all filepaths are defined in a single location. These filepaths (or more correctly, python Path objects) are then imported by every python script in this package. So any future users will not have to edit multiple files to use this code.
If your python environment requirements are more complex, you can place conda configuration or other package requirement files here.
Python files#
The actual python code which defines this project is contained in the subdirectory solar_example. This might strike you as strange, as it means we have ‘doubled up’ on the project name, as we now have a local directory structure that looks like /software_engineering_demos/solar_example/solar_example. However, there are good reasons for doing this, and they are related to project namespaces and combining multiple packages (or directories) into a single python project. Maintaining this fine scale control over which directories we add to the PYTHONPATH or sys.path avoids us having to import too many modules, or conflicts occurring between modules which may have the same directory name
See this Reddit Post for further discussion.
In this project, there are three python source files, along with a special file __init__.py.
From the official python docs:
“The init.py files are required to make Python treat directories containing the file as packages (unless using a namespace package, a relatively advanced feature). This prevents directories with a common name, such as string, from unintentionally hiding valid modules that occur later on the module search path.”
The link explains the contents of the __init__.py file for our simple example. Entries in this file help control the scope of files to be imported and manage ‘intra-package’ references when using our package.
Scripts#
In the /software_engineering_demos/solar_example/scripts/, we have files which import the files contained in /software_engineering_demos/solar_example/solar_example as a module. We have a python script concurrent_test.py which can process the data inside an interactive python session (i.e. iPython). This script is discussed here. We also have a bash script concurrent_test.sh.qsub which can be submitted to the PBS queue on gadi.
Ancils#
Sometimes your package requires small ancillary files which are essential to the functioning of the package. In this case, we have a .npz file (which is a binary zipped archive of python numpy arrays) which defines the location of solar energy zones specific to the package. Small ancillary files (~ 100 Mb>) can be stored within a package directory on GitHub. Typically we want to ensure the package repository itself remains < 1 Gb, so if your package is reliant on larger ancillary files, special data storage repositories outside of GitHub would be required.
Tests#
As discussed here, all good packages come with some simple test functions to ensure they are working as expected. These tests can be executed using pytest as discussed here. Testing is another component of ‘portability’, i.e. it ensures that shared code is deployed correctly across multiple users and platforms.
The final directory structure of the solar_example package resembles this example, taken from here
Conclusions#
The simple solar_example package provides a useful template for building python packages over the course of your research. Over time, you can add extra sub-directories to deal with extra complexity, but this structure is a good starting point.
You can find more information here :
https://dagster.io/blog/python-project-best-practices
and